
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ansible
- Algorithm
- While
- 연산자
- JavaScript
- Kotlin
- MergeSort
- Spring Security
- Sprint Security
- SpringBoot Initializr
- lambda
- JPA
- quicksort
- C++
- jvm
- 기초
- programmers
- datastructure
- IAC
- If
- Java
- 자료형
- redis
- datatype
- zgc
- Fluent-bit
- For
- UserDetails
- g1gc
- Class
- Today
- Total
뭐라도 끄적이는 BLOG
JPA 소개 본문

JPA는?
과거에는 EJB라는 기술표준의 엔티티 빈이라는 ORM기술을 사용했지만 너무 복잡하고 기술 성숙도도 떨어졌으며 자바 엔터프라이즈 애플리케이션(J2EE) 서버에서만 동작한다는 문제점이 있었다. 여기서 ORM(Object-Relational Mapping)은 이름 그대로 객체와 관계형 데이터베이스를 매핑한다는 뜻이다. EJB를 사용하던 한 개발자가 이러한 문제들을 해결하고자 hibernate라는 오픈소스를 탄생시켰다. 이후 EJB3.0부터 하이버네이트를 기반으로 하여 새로운 자바 ORM 기술표준을 만들었는데 이것이 JPA이다. JPA(Java Persistence API)는 자바 진영의 ORM 기술 표준이다. ORM 프레임워크는 객체와 테이블을 매핑해서 패러다임의 불일치 문제를 개발자 대신 해결해 준다.
JPA는 Java진영의 ORM 기술 표준이다. 쉽게 이야기해서 인터페이스를 모아둔 것이다. 따라서 JPA를 사용하려면 JPA를 구현한 ORM 프레임워크를 선택해야 한다. EclipseLink, DataNucleus등이 있지만 이중에서도 하이버네이트가 가장 대중적 이다.

ORM(Object-relational mapping)
ORM 이란 객체는 객체대로 설계를 하고 관계형 DB는 관계형 DB답게 셜계를 한 다음 중간에 나타나는 차이들을 ORM프레임 워크가 매핑해주는 것이다. 대부분의 대중적인 언어에서 ORM기술이 존재한다.
JPA의 동작 구조
JPA는 애플리케이션과 JDBC사이에서 동작한다.
JPA구조
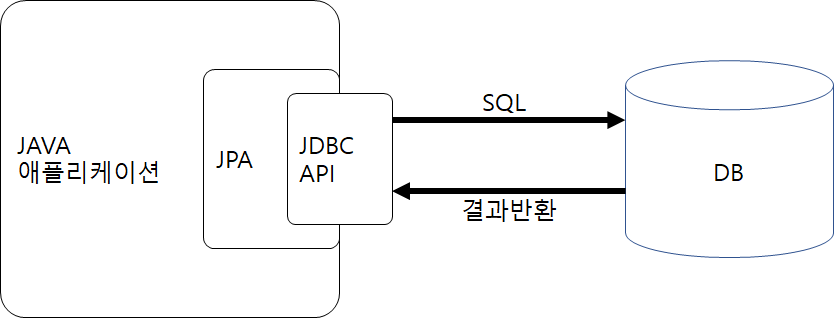
개발자가 직접 JDBC API를 사용하는 것이 아닌 JPA에 명령을 내리면 JPA가 JDBC API를 사용해서 SQL을 만들어 보내고 결과를 반환 받는다.
JPA INSERT
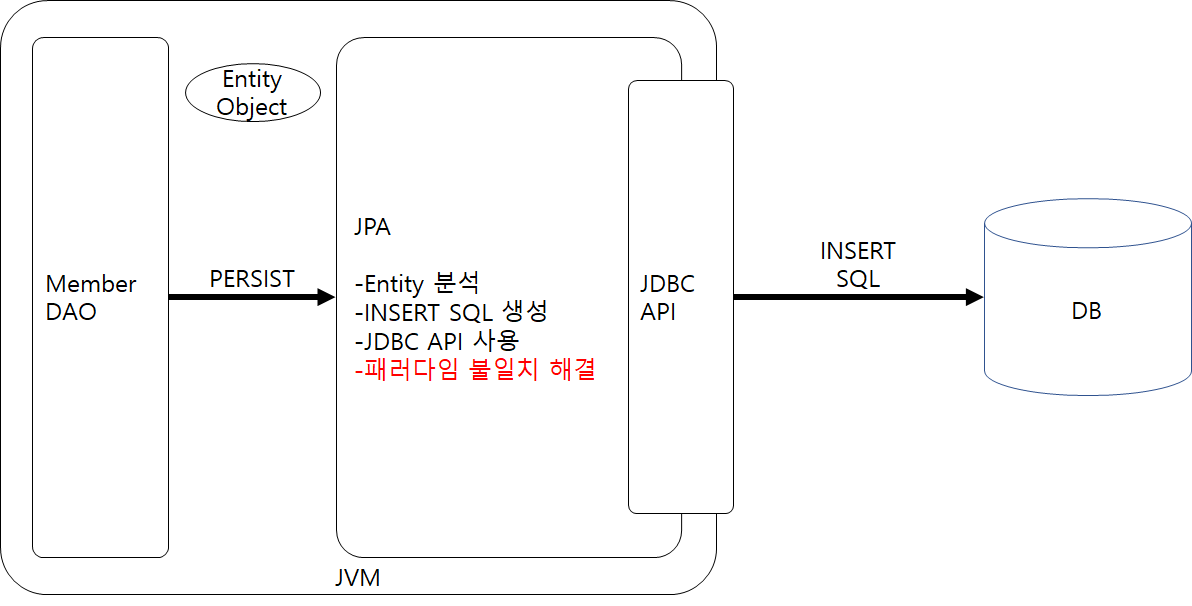
JPA가 객체를 분석하여 적절한 INSERT 쿼리를 생성하여 DB에 요청한다.
JPA 조회

JPA가 객체를 보고 SELECT 쿼리를 생성하여 JDBC API를 통해 조회를 한뒤 ResultSet에 매핑한다. 여기서 중요한 점은 이러한 과정으로 패러다임의 불일치 문제를 해결해 준다는 것이다.
JPA를 사용해야하는 이유
SQL 중심적인 개발에서 객체 중심으로 개발이 가능해 진다.
생산성
CRUD에 해당하는 쿼리들을 JPA가 대신 생성해 준다. 프로그래머는 단순히 아래의 코드들 만으로 CRUD를 시도하면 된다.
jpa.persist(member) //저장
Member member = jpa.find(memberId); //조회
member.setName("name") //수정
jpa.remove(member) //삭제JPA에는 CREATE TABLE과 같은 DDL문을 자동으로 생성해 주는 기능또한 있다. 이러한 기능들을 사용하면 데이터베이스 설계 중심의 패러다임을 객체 설계 중심으로 역전시킬 수 있다.
DDL문을 자동으로 생성하지만 테스트용도에서 정도만 이용하지 실사용 용도로는 부적절한 면이 있다.
유지보수
SQL을 직접 다루면 엔티티에 필드를 하나만 추가해도 관련된 등록, 수정, 조회 SQL과 결과를 매핑하기 위한 JDBC API코드를 모두 변경해야 한다. 반면 JPA는 이런 과정을 대신 처리해주므로 필드를 추가하거나 삭제해도 수정해야 할 코드가 줄어든다. 개발자가 작성해야 했던 SQL과 JDBC API코드를 JPA가 대신 처리해주므로 유지보수해야 하는 코드 수가 줄어들된다.
패러다임의 불일치 해결
상속, 연관관계, 객체 그래프 탐색, 비교하기와 같은 패러다임의 불일치 문제를 해준다. 앞으로 설명할 JPA 전반에 걸쳐 패러다임의 불일치 문제를 어떻게 해결하는지 알게된다.
성능
애플리케이션과 데이터베이스 사이에서 동작하기 때문에 최적화관점에서 시도해 볼 수 있는 것들이 많다.
1차 캐시와 동일성 보장
같은 트랜잭션 안에서 같은 회원을 두 번 조회하는 코드는 JDBC API에서 작성했다면 조회할 때 마다 SELECT SQL으로 데이터베이스와 통신할 한다. 그리고 SELECT SQL의 결과로 만들어진 객체는 데이터는 같지만 서로 다른 객체가 된다. JPA를 사용하면 회원을 조회하는 SELECT SQL을 한번만 전달하고 두 번째는 조회한 회원 객체를 재사용한다. 그리고 같은 데이터이며 객체참조또한 같다.
트랜잭션을 지원하는 쓰기 지연
쉽게 말하면 버퍼링 기능이다. JDBC BATCH SQL기능을 사용해서 한번에 SQL을 전송하여 통신을 줄일 수 있다. 트랜잭션의 시작과 트랙잭션 커밋 사이의 쿼리를 한번에 전송할 수 있다.
지연 로딩
객체가 실제로 사용될 때 로딩되는 지연로딩과 JOIN SQL로 한번에 연관된 객체까지 미리조회하는 즉시로딩이 있다. 예를 들어 연관관계를 가진 Member와 Team이 있다고 가정면, Member를 사용하기 위해서 데이터베이스에서 값을 불러올때 연관관계를 가진 Team은 가지고 오지 않고 Member만 먼저 가져오고 이후 Member에 의해 Team이 사용되어질때 Team을 데이터베이스에서 불러오는 것을 지연로딩이라고 한다.
즉시로딩은 Member를 데이터베이스에서 불러올때 Team도 같이 불러오게 된다. JPA에선 단순히 옵션의 변경으로 지연로딩과 즉시로딩을 변경할 수 있다.
데이터 접근 추상화와 벤더 독립성
RDB는 같은 기능도 벤더마다 사용법이 다른 경우가 많다. 그렇기 때문에 애플리케이션은 처음 선택한 데이터베이스 기술에 종속되고 다른 데이터베이스로 변경하기가 매우 어렵다.
JPA에서는 애플리케이션과 데이터베이스 사이에 추상화된 데이터 접근 계층을 제공해서 애플리케이션이 특정 데이터베이스 기술에 종속되지 않도록 한다. 만약 데이터베이스를 변경하면 JPA에게 다른 데이터베이스를 사용한다고 알려주기만 하면 된다.
단순히 데이터베이스 변경을 알려준다고 해서 완전히 변경할 수 있는것은 아니긴하지만 데이터베이스 방언등 어려 가지 통합해주는 부분이 있기때문에 코드의 변경이 많이 줄어든다.
이외에도 DB Isolation Level이 Read Commit이어도 애플리케이션에서 Repeatable Read를 보장합니다.
참고자료
자바 ORM 표준 JPA 프로그래밍 - 기본편 - 인프런 | 강의
JPA를 처음 접하거나, 실무에서 JPA를 사용하지만 기본 이론이 부족하신 분들이 JPA의 기본 이론을 탄탄하게 학습해서 초보자도 실무에서 자신있게 JPA를 사용할 수 있습니다., 본 강의는 자바 백엔
www.inflearn.com
자바 ORM 표준 JPA 프로그래밍 - 교보문고
스프링 데이터 예제 프로젝트로 배우는 전자정부 표준 데이터베이스 프레임 | ★ 이 책에서 다루는 내용 ★■ JPA 기초 이론과 핵심 원리■ JPA로 도메인 모델을 설계하는 과정을 예제 중심으로
www.kyobobook.co.kr
Documentation - 5.6 - Hibernate ORM
Idiomatic persistence for Java and relational databases.
hibernate.org
'Java > JPA' 카테고리의 다른 글
| RDA와 Object oriented 비교 (0) | 2023.07.17 |
|---|---|
| JPA 06.02 - 다양한 연관관계 매핑 [ 1 : 1, N : M ] (0) | 2021.04.17 |
| JPA 06.01 - 다양한 연관관계 매핑 [ N : 1, 1 : N ] (0) | 2021.04.17 |
| JPA 05.02 - 양방향 연관관계와 연관관계의 주인 (0) | 2021.04.16 |
| JPA 05.01 - 연관관계 매핑, 단방향 연관관계 (0) | 2021.04.16 |



